Reproducible Performance Benchmarking for Genomics Workflows on HPC Cluster
Project Idea description
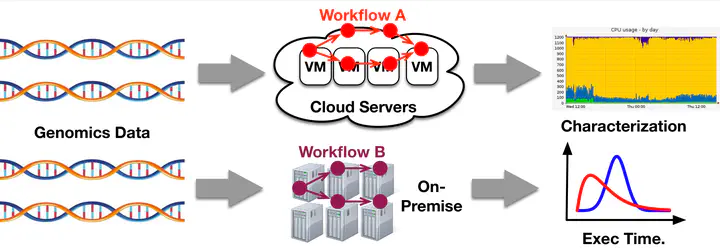
We aim to characterize the performance of genomic workflows on HPC clusters by conducting two research activities using a broad set of state-of-the-art genomic applications and open-source datasets.
Performance Benchmarking and Characterizing Genomic Workflows:
- Topics: High Performance Computing (HPC), Data Analysis, Scientific Workflows
- Skills: Linux, Python, Bash Scripting, Data Science Toolkit, Kubernetes, Container Orchestration, Genomics Applications (e.g. BWA, FastQC, Picard, GATK, STAR)
- Difficulty: Medium
- Size: Large (350 hours)
- Mentor(s): In Kee Kim
In this activity, students will perform comprehensive performance measurements of genomic data processing on HPC clusters using state-of-the-art applications, workflows, and real-world datasets. They will collect and package datasets for I/O, memory, and compute utilization using industry-standard tools and best practices. Measurement will be done using Kubernetes container orchestration on a multi-node cluster to achieve scalability, with either custom-made metrics collection system or integration of existing industry standard tools. (e.g. Prometheus).
Quantifying Performance Interference and Assessing Their Impact on Workflow Execution Time:
- Topics: Machine Learning, Data Analysis, and Scientific Workflows and Computations
- Skills: Linux, Python, Bash Scripting, Data Science Toolkit, Kubernetes, Container Orchestration
- Difficulty: Difficult
- Size: Medium (175 hours)
- Mentor(s): In Kee Kim
In this activity, students will measure the slowdown of various applications due to resource contention (e.g. CPU and I/O). Students will analyze whether an application is compute-bound, I/O bound, or both, then analyze the correlation between resource utilization and execution time. Following that, students will assess the impact of per-application slowdown to the slowdown of a whole workflow. To the best of our knowledge, this will be the first study which systematically quantifies per-application interference when running genomics workflow on an HPC cluster.
For both subprojects, all experiments will also be conducted in a reproducible manner (e.g., as a Trovi package or Chameleon VM images), and all code will be open-sourced (e.g., shared on a public Github repo).
Project Deliverable:
A Github repository and/or Chameleon VM image containing source code for application executions & metrics collection. Jupyter notebooks and/or Trovi artifacts containing analysis and mathematical models for application resource utilization & the effects of data quality.
In Kee Kim
Assistant Professor, University of Georgia
In Kee Kim is currently an Assistant Professor in the School of Computing at the University of Georgia. He obtained his Ph.D. in Computer Science from the University of Virginia in 2018.